Junk Dimension
Cardinality: Number of Unique Values.
A junk dimension is a dimension table created by grouping low cardinality and unrelated attributes.
The idea behind a junk dimension is to reduce the number of dimension tables in a data warehouse and simplify queries.
An example of a junk dimension could be a table that includes binary flags such as "is_promotion", "is_return", and "is_discount".
Possible Values for is_promotion as Y or N same for is_return and is_discount.
Example:
fact_sale table
Date
Product
Store
OrderNumber
PaymentMode
StoreType
CustomerSupport
Quantity
UnitPrice
Possible values for these columns
PaymentMode - Cash/Credit/Check
StoreType - Warehouse/Marketplace
CustomerSupport - Yes/No
So how to handle the situation
Option 1: Add it to Fact Table
The problem is, Fact table data is not that important and sometimes won't make sense
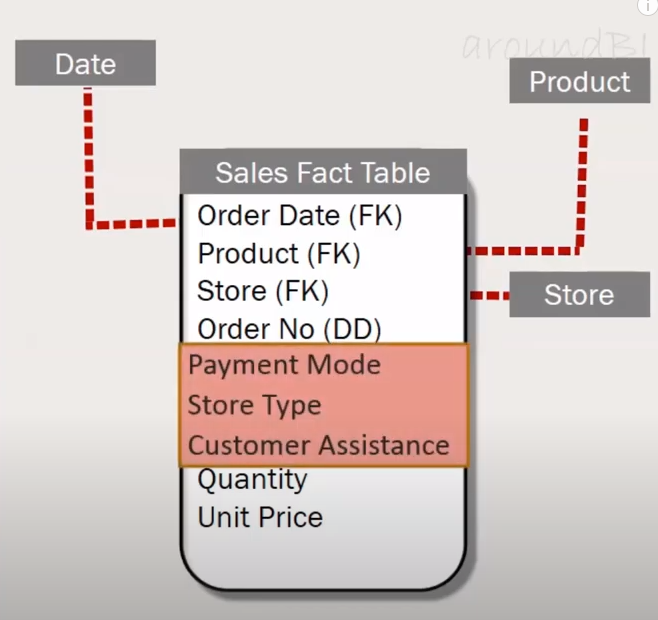
src: aroundbi.com
Option 2: Add it as Dimension Table
The problem is with more Dimension table adds more joins to your queries.
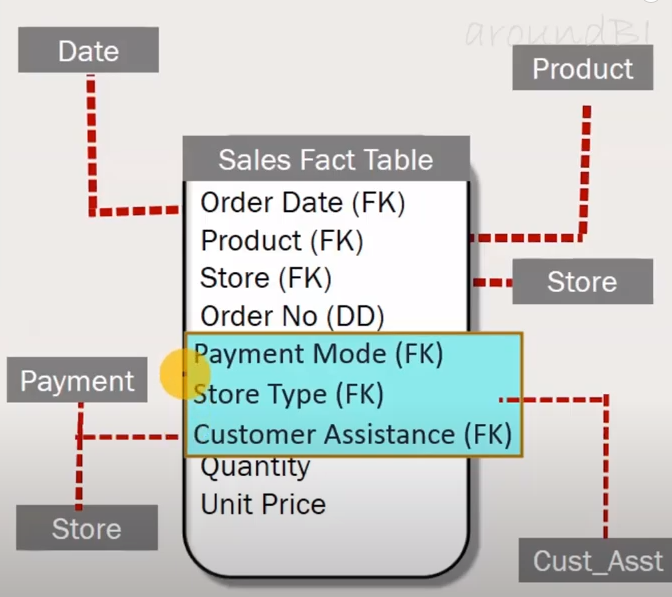
src: aroundbi.com
Do you know how to take care of this situation?
Let's create a new table with values from all possible combinations.
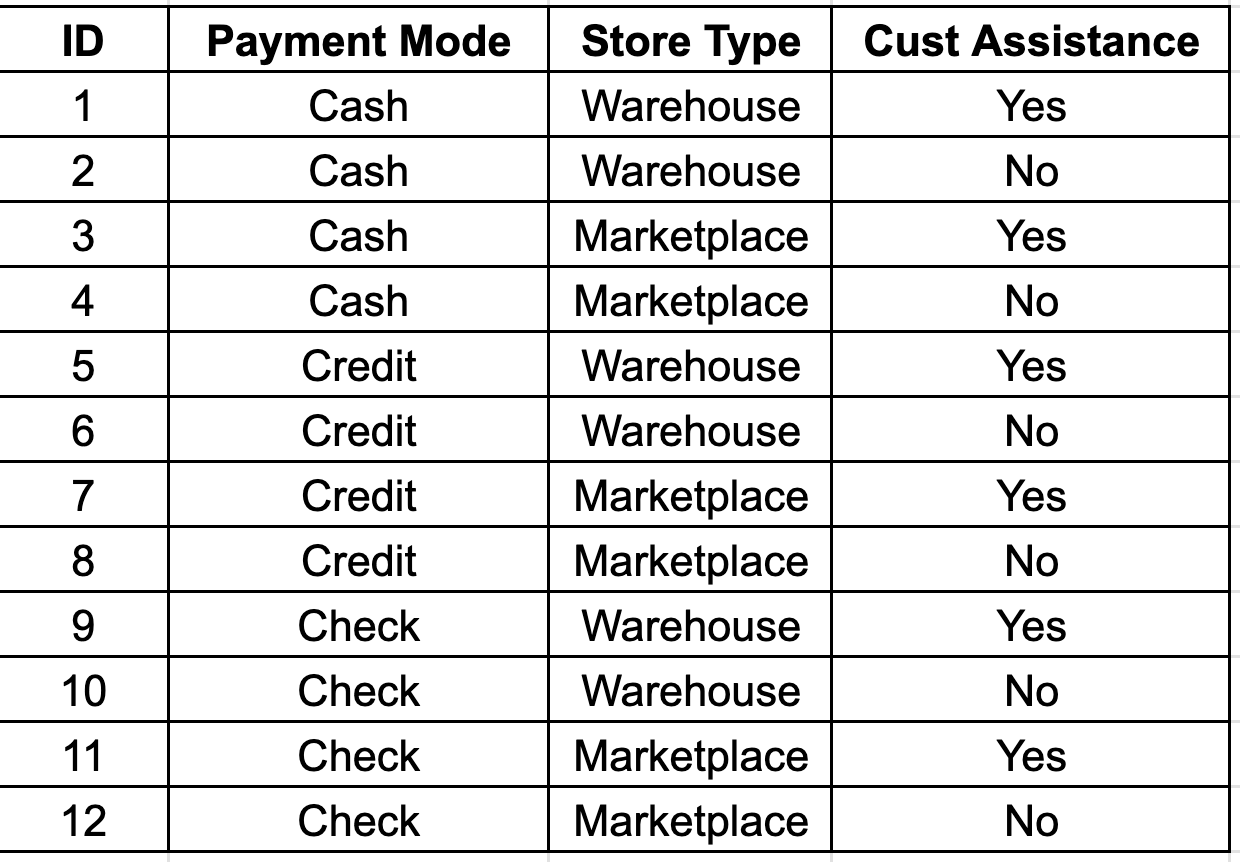
Junk Dimension with ID
So, the revised Fact Table looks like this
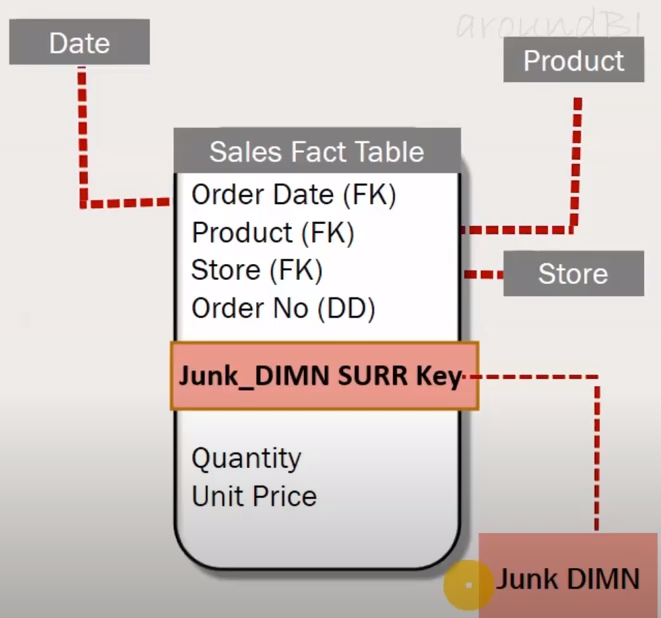
- Basically to group low cardinality columns.
- If the values are too uncorrelated.
- Helps to keep the DW simple by minimizing the dimensions.
- Helps to improve the performance of SQL queries.
Note: If the resultant dimension has way too many rows, then don’t create a Junk dimension.